本文将对virtio技术进行剖析和介绍,包括virtio的原理、接口和linux下的虚拟网路实现virtio-net。
本文主要依据Russell的论文内容进行介绍,具体的virtio插口和实现在过去的十多年里必然早已大不相同了,但根本的思想和原理并没有变。
问题virtio作为通用的IO虚拟化模型,是怎样定义通用的IO控制面和数据面插口的?或则说,基于virtio的网路设备virtio-net和块储存设备virtio-blkred hat linux下载,有什么共通点?在linux内核下,有virtio、virtio-pci、virtio-net、virtio-blk等virtio相关驱动。这种驱动是怎么组织的,多个驱动间是哪些关系?一个virtio设备,是怎样加入到虚拟机设备模型中,被内核发觉和驱动的?virtio-net具体又提供了什么标准插口?控制面和数据面插口是怎样定义的?virtio技术为虚拟化而形成,但它能够脱离虚拟化环境使用?诸如在普通的容器环境或则化学机环境?virtio
virtio作为一种通用的虚拟IO设备驱动模型,主要定义了两方面的标准模型和插口:控制面的设备配置和初始化,以及数据面的数据传输。
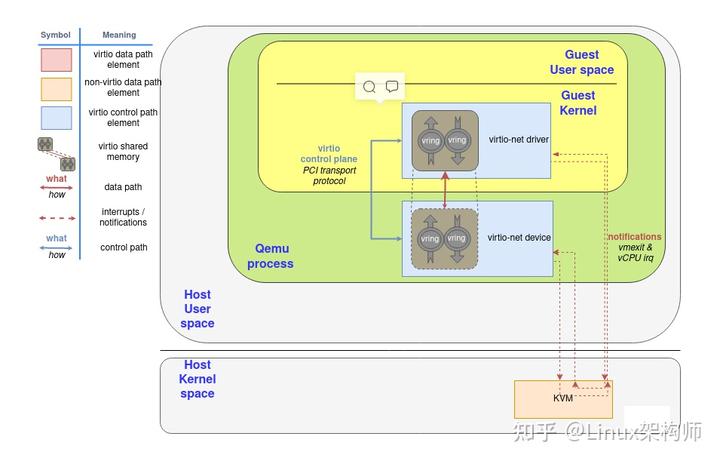
上图是在qemu/kvm虚拟机中实现virtio的构架。可见基本逻辑和其他虚拟网卡是相同的,只是交互方法通过vring队列实现。
控制面定义
virtio的控制面插口可以分为4个部份:
1.读写特点位
特点位用于device和driver间同步设备特点,比如VIRTIO_NET_F_CSUM表示网卡是否支持checksumoffload。driver读取特点位来获取网卡前端支持的特点,driver写入特点位来通知网卡前端须要使用的特点。
2.读写配置
配置是一个表示设备配置信息的数据结构。driver和device间通过这个结构来获取和设置设备的配置,比如网卡的MAC地址等。
3.读写状态位
状态位用于driver通知前端自己的初始化进度。driver将状态位设置为VIRTIO_CONFIG_S_DRIVER_OK就表示driver早已完成特点初始化,host在收到这个消息后就可以确定driver须要使用的设备特点。
4.重启设备
用于移除或则重置virtio设备驱动。

每位virtio设备会有一个virtio_config_ops,其中包括了对上述控制面插口的实现。这种插口的实现和系统提供virtio设备的方法有关,倘若是最常见的virtio-pci模式,则这种实现基本上都是对下边会介绍的virtio_pci_common_cfg配置空间的IO读写操作。
virtqueue:数据传输模型
virtio中定义了virtqueue作为guest驱动和host前端间的数据传输结构。块设备只须要一个virtqueue用于数据读写,而网路设备则须要两个virtqueue分别用于网路报文的收和发。
virtqueue是一个队列的具象模型。guest驱动负责向virtqueue中插入一个个数据buffer,而host前端则负责处理这种buffer。每位buffer都可以由多段不连续的数据空间链接而成,每段数据空间可以有不同的读写权限用于不同的用途。诸如用于块设备读取的buffer,可以包含一段guest负责写入的读取信息(位置、长度等),以及一段host负责写入的读取数据内容。buffer的具体结构和设备类型相关。
virtqueue须要支持5个插口,进而实现数据在guest和host间的传输:
struct virtqueue_ops {
int (*add_buf)(struct virtqueue *vq,
struct scatterlist sg[],
unsigned int out_num,
unsigned int in_num,
void *data);
void (*kick)(struct virtqueue *vq);
void *(*get_buf)(struct virtqueue *vq,
unsigned int *len);
void (*disable_cb)(struct virtqueue *vq);
bool (*enable_cb)(struct virtqueue *vq);
};add_buf用于向virtqueue中插入一个待host处理的buffer,参数data是一个由驱动定义的标示符,用于标示buffer;
kick用于通知host有新的buffer加入,须要处理;
get_buf用于从virtqueue中获取一个host处理完成的buffer,返回值就是add_buf时传入的data参数;
disable_cb和enable_cb类似于普通设备驱动中的关中断和开中断,用于设置virtqueue的callback函数在host处理完一个buffer后是否会被调用。callback函数是在driver初始化时注册给virtqueue的。
virtio_ring:数据传输实现
virtqueue是数据传输的具象模型,而virtio_ring则是这个模型的一种高效实现。
一个virtio_ring由三个部份构成:descriptor资源链表、availablering和usedring。
struct vring_desc
{
__u64 addr;
__u32 len;
__u16 flags;
__u16 next;
};每位descriptor可以指示一段显存空间的地址(addr)和宽度(len)。多个descriptor可以产生一个链(next),用于表示virtqueue模型中的一个buffer。descriptor还有一个数组flags,用于指示当前descriptor是否是链尾,以及数据段是可读的还是可写的。
struct vring_avail
{
__u16 flags;
__u16 idx;
__u16 ring[NUM];
};这是一个环型队列,ring[NUM]中每位位置保存一个descriptor链的索引(在descriptor资源链表中的下标),idx用于指示最后插入的descriptor链的位置。flags用于guest通知host是否须要在处理完buffer后形成中断。
virtqueue的add_buf就是通过availablering来实现。
struct vring_used_elem
{
__u32 id;
__u32 len;
};
struct vring_used
{
__u16 flags;
__u16 idx;
struct vring_used_elem ring[];
};和availablering一样,usedring也是一个环型队列。flags用于host通知guest是否须要在降低buffer后kick。惟一不同的是,usedring中的每位元素不仅包括descriptorindex之外,还包括了一个len数组,用于表示host处理后的descriptor链中有效数据的总宽度。
virtqueue的get_buf就通过这个ring实现。
descriptor的所有权就仍然按《descriptor字段->availablering->usedring->descriptor字段》这个循环不断流转,如右图所示。
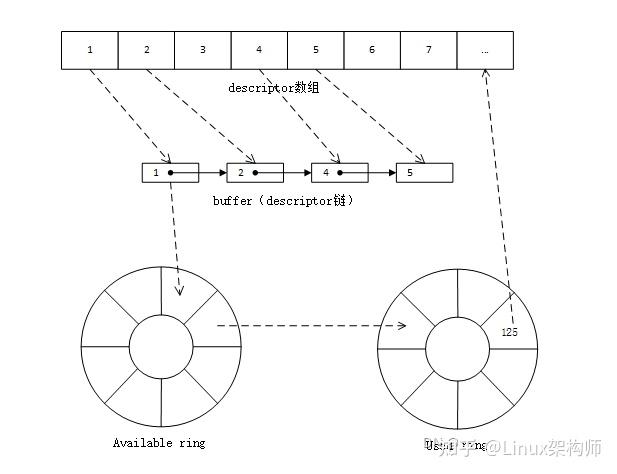
值得注意的是,和常见的环型队列不同,vring中并没有对端的消费进度数组。因而guestdriver和hostbackend事实上在向vring中插入元素时是不晓得vring中的剩余空间情况的。之所以不用害怕vring插入时出现溢出的问题,是由于vring实现时将descriptor链表、availablering和usedring设置成了相同大小。因而只要还有descriptor可以向vring中插入linux pci设备,就说明vring上一定还有空余的位置。
还有一点要说明的是,descriptor链被guest插入availablering的次序和被host处理完成并插入usedring的次序不一定是相同的,由于后发出的恳求有可能被先执行完成(比如块设备读写,后发的的小块读写可能在先发的大块读写前完成)。这么这儿就有个疑惑:是否可能次序靠后的descriptor被回收了造成availablering可以被写入而覆盖了次序在前的descriptor?这也是不可能的,vring是一个先进先出队列,次序靠前的descriptor永远被先开始处理,因而当前面的descriptor被回收时linux pci设备,在它上面的descriptor肯定早已被对端处理过了,其descriptorindex信息早已不再须要,availablering将descriptorindex覆盖也不影响对端对descriptor本身的处理。
virtio设备驱动
基于前文介绍的virtio插口定义和vring实现,可以实现各种类型的virtio设备驱动。目前被广泛使用的virtio驱动主要有两种:virtio-blk用于virtio块设备,以及virtio-net用于virtio网路设备。
virtio-blk
virtio-blk只须要一个virtqueue来发送块读写恳求并获取结果。其中每位buffer(descriptor链)由三部份构成:恳求信息virtio_blk_outhdr、读写数据段信息和结果状态。通常实现中会把这三部份分别放置在三个descriptor中。
1.virtio_blk_outhdr
struct virtio_blk_outhdr
{
__u32 type;
__u32 ioprio;
__u64 sector;
};host只读的descriptor

type数组表示恳求的类型:读、写、或者其他c盘操作命令。
ioprio数组表示恳求的优先级,数值越大优先级越高,前端可以依据该数组决定恳求处理顺序。
sector数组表示读写恳求的偏斜位置。这儿的sector表示偏斜位置以磁道(512字节)为单位。
2.数据段
纯粹的数据段,操作类型决定host可读或可写。
3.结果状态
只有1个字节,host可写,用于host反馈恳求的处理结果是成功(0)、失败(1)或不支持(2)。
virtio-net
virtio-net须要两个virtqueue分别用于网路报文的发送和接收。virtio-net中的buffer也有一个header,用于传递checksumoffload和segmentationoffload。
struct virtio_net_hdr
{
// Use csum_start, csum_offset
#define VIRTIO_NET_HDR_F_NEEDS_CSUM 1
__u8 flags;
#define VIRTIO_NET_HDR_GSO_NONE 0
#define VIRTIO_NET_HDR_GSO_TCPV4 1
#define VIRTIO_NET_HDR_GSO_UDP 3
#define VIRTIO_NET_HDR_GSO_TCPV6 4
#define VIRTIO_NET_HDR_GSO_ECN 0x80
__u8 gso_type;
__u16 hdr_len;
__u16 gso_size;
__u16 csum_start;
__u16 csum_offset;
};flags、csum_start、csum_offset用于checksumoffload,当flags为VIRTIO_NET_HDR_F_NEEDS_CSUM时前端从csum_start位置开始估算checksum并填入csum_offset位置处。
gso_type、hdr_len、gso_size用于segmentationoffload,gso_type指示分段的类型,hdr_len表示首部的宽度(首部是不能分段的部份,每位报文都要携带),gso_size表示分段后的数据宽度(不包括首部)。
前端按照上述数组对descriptor链中的报文数据进行offload的功能处理,其实前提是virtio-net初始化时guest和host协商使用了这种offload功能。
virtio-pci:virtio的PCI设备实现
PCI是目前最常用的通用总线,大部份hypervisor都支持了PCI设备的模拟和降低。为此,virtio也提供了基于PCI总线的侦测配置插口和实现,因而提供一套完整的设备发觉、配置和运行能力。
virtio-pci上的PCI设备ID为1AF4:1000~1AF4:10FF。1AF4是vendorid,由Qumranet提供,通常virtio前端都默认使用这个ID作为virtio设备的vendorid,Linux中的virtio驱动也只支持这个ID的设备。但也有例外,比如阿里云的神龙网卡提供的virtio-net设备,vendorid就是阿里巴巴自己的vendorid(1DED),驱动这种设备时就须要更改网卡驱动中支持的ID列表。
当PCI总线上出现ID在这个范围的设备时,virtio-pci都会觉得是virtio设备并为其注册一个virtio_device设备信息到virtio总线上。virtio-pci本身并不须要晓得virtio设备究竟是哪些类型,而是会遍历早已加载的virtio-net、virtio-blk等virtio驱动来找到合适的驱动。virtio总线只是virtio-pci中的逻辑,因而在linuxkernel看来,所有的PCIvirtio设备的驱动都是virtio-pci。
virtio-pci设备同样须要通过设备IO来协商设备与驱动的特点和配置。IO空间大约是这样的结构:
struct virtio_pci_io
{
__u32 host_features;
__u32 guest_features;
__u32 vring_page_num;
__u16 vring_ring_size;
__u16 vring_queue_selector;
__u16 vring_queue_notifier;
__u8 status;
__u8 pci_isr;
__u8 config[];
}其中的数组分别用于获取和配置设备特点、vring地址、kickIO地址、设备状态等。这个结构在Russell的论文中只是概念性的定义。Linux内核的实现中早已有了一些改变。在手头的5.9.11内核中,对应的结构为:
/* Fields in VIRTIO_PCI_CAP_COMMON_CFG: */
struct virtio_pci_common_cfg {
/* About the whole device. */
__le32 device_feature_select; /* read-write */
__le32 device_feature; /* read-only */
__le32 guest_feature_select; /* read-write */
__le32 guest_feature; /* read-write */
__le16 msix_config; /* read-write */
__le16 num_queues; /* read-only */
__u8 device_status; /* read-write */
__u8 config_generation; /* read-only */
/* About a specific virtqueue. */
__le16 queue_select; /* read-write */
__le16 queue_size; /* read-write, power of 2. */
__le16 queue_msix_vector; /* read-write */
__le16 queue_enable; /* read-write */
__le16 queue_notify_off; /* read-only */
__le32 queue_desc_lo; /* read-write */
__le32 queue_desc_hi; /* read-write */
__le32 queue_avail_lo; /* read-write */
__le32 queue_avail_hi; /* read-write */
__le32 queue_used_lo; /* read-write */
__le32 queue_used_hi; /* read-write */
};数组比前面的更详尽,但用途基本是对应的。
小结
上文主要基于RustyRussell在2008年的virtio论文,介绍了virtio的相关技术原理。virtio技术在这十几年中得到了广泛的应用,但其在linux内核中的驱动实现却和十几年前设计时几乎没有区别,可见virtio设计的通用性、兼容性和可扩充性都十分优秀。
最后我们尝试回答一下开头提出的问题:
1.virtio作为通用的IO虚拟化模型,是怎样定义通用的IO控制面和数据面插口的?或则说,基于virtio的网路设备virtio-net和块储存设备virtio-blk,有什么共通点?
对于控制面,virtio为每位设备封装了virtio_config_ops插口,用于配置和启动设备。
对于数据面,virtio定义了virtqueue具象传输模型,virtqueue提供了一系列操作插口来完成数据收发和风波通知。virtio_config_ops中的find_vqs插口提供了virtqueue的创建和获取能力。virtqueue具体通过virtio-ring实现,driver向availablering中输入恳求,hostbackend处理恳求后向usedring中输入回应。
上述模型和实现是virtio设备通用的,virtio-net和virtio-blk都基于这套模型和插口实现。不同之处只在于使用的virtqueue数目,以及virtqueue/vring中的恳求/回应的结构与内容不同,那些都和设备的具体功能和行为密切相关。
2.在linux内核下,有virtio、virtio-pci、virtio-net、virtio-blk等virtio相关驱动。这种驱动是怎么组织的,多个驱动间是哪些关系?
linux内核中和virtio相关的驱动主要有:virtio、virtio_ring、virtio_pci、virtio_net、virtio_blk等。其中:
virtio提供了virtio总线和设备控制面的插口。

virtio_ring提供了数据面,也就是virtqueue插口和对应的vring实现。
virtio_pci提供了virtio设备作为PCI设备加载时的通用驱动入口,它依赖virtio和virtio_ring提供的插口。
virtio_net提供了virtio网路设备的标准驱动,它依赖virtio和virtio_ring提供的插口。virtio_net将自己注册为virtio总线的一种设备驱动。
virtio_blk提供了virtio块储存设备的标准驱动,它依赖virtio和virtio_ring提供的插口。virtio_blk将自己注册为virtio总线的一种设备驱动。
3.一个virtio设备,是怎样加入到虚拟机设备模型中linux deepin,被内核发觉和驱动的?
一个virtioPCI设备加载时,内核会尝试所有注册的PCI设备驱动,最后发觉可以被virtio_pci驱动。virtio_pci再调用注册到virtio总线上的设备驱动,最后发觉可以被virtio_net驱动。virtio_net通过virtio_pci的标准配置插口和host协商设备特点和初始化设备,然后通过virtio_ring提供的插口收发网路数据。
4.virtio-net具体又提供了什么标准插口?控制面和数据面插口是怎样定义的?
virtio设备的控制面和数据面插口都是标准的,只是具体数据格式和涵义有区别。virtio-net有自己的featurebit集合,每位virtio-net设备起码使用两个virtqueue用于报文的收和发。virtio-net收发的数据buffer都包括virtio_net_hdr作为颈部,用于表示driver和host设置的offload参数。
5.virtio技术为虚拟化而形成,但它能够脱离虚拟化环境使用?诸如在普通的容器环境或则化学机环境?
理论上说,virtio设备须要driver和host前端两部份协同完成。在非虚拟化环境下,这个前端可以是内核的vhost模块。vhost模块是在内核中实现的virtio前端功能,是为了进一步提高virtio设备的效率而形成的:
virtio为虚拟IO设备提供了一套标准的插口和实现。同时因为其半虚拟化的特质,virtio驱动在设计和实现时尽可能降低了主要操作路径上会触发host前端操作(vmexit)的指令以提高IO效率。但在执行IO操作时,仍会不可防止的须要触发前端操作。诸如virtio-net驱动分包时,在向txvirtqueue写入buffer后必然要kick前端来处理buffer,这个kick就是一个IO写操作。当前端在用户态qemu进程中实现时,这就须要经过guestdriver->kvm->qemu->kvm->guest的过程,和普通的虚拟设备驱动是没有区别的,效率依然低下。为了减短这个过程,前端实现被装入了内核态,作为一个内核模型/内核线程运行,也就是vhost。有了vhost后,前端操作的流程就弄成了guestdriver->kvm->vhost->kvm->guest。看似和之前差不多,而且kvm和vhost之间的交互只是一个内核函数调用,性能比之前的kvm和qemu间的用户/内核切换要好的多。同时,使用vhost也提高了前端完成实际IO操作的性能。大部份情况下,前端完成IO操作(比如块设备读写或网路收发)一直要通过内核插口,比如qemu依然须要使用文件或socket插口实现,这又须要引入系统调用和状态切换。而使用vhost以后,这种内核能力可以由vhost模块直接调用,又一次降低了状态切换花销。
基于vhost,virtio设备虽然不一定须要在虚拟化环境下使用,可以在用户态实现virtio驱动,在初始化时直接与vhost交互完成配置,这样就可以在非虚拟化环境下实现一个用户态的纯虚拟virtio设备。
Dpdk/网路合同栈/vpp/OvS/DDos/NFV/虚拟化学习地址:/course/5066203?flowToken=1043068
本文转载自:/dillanzhou/article/details/120339795
DPDK/网路合同学习资料、教学视频和学习路线图分享有须要的可以自行添加学习交流群973961276获取