ROW被称之为写时重定向。ROW的实现原理与COW十分相像,区别在于ROW对原始数据卷的首次写操作,会将新数据重定向到预留的快照卷中。所以,ROW快照中的原始数据仍然保留在源数据卷中,但是为了保证快照数据的完整性,在创建快照时linux操作系统简介,源数据卷状态会由读写弄成只读的。
创建快照时,ROW也会复制一份源数据映射表作为快照数据映射表,此时两张表的表针记录都相同的。如下所示。
图1-6快照初始状态

用户在Time0时刻执行创建快照的操作后,储存系统内部处理流程如下:
按照源卷映射表拷贝出快照映射表。生成快照卷,用于储存新写入的数据。
写源卷
图1-7写入源卷

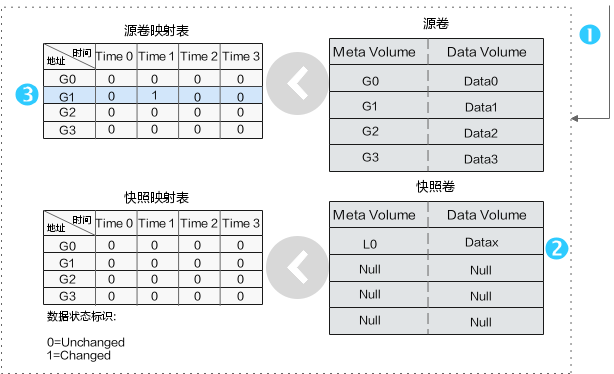
应用服务器在Time1下发写快照卷的恳求:将数据“Data1”改写为数据“Datax”。源数据卷中的原始数接收到更新操作指令,将新数据写入到申请的新快照卷中。更新源卷映射表。
后续随着数据的写入不断重复执行到,直至上次快照生成。从上述步骤可以晓得源卷储存的是上一个快照时间点Time0的旧数据,新数据最终储存在预留的快照卷中。源卷的数据映射表和其对应的数据是没有被改变过的。
假如对一个虚拟机做了多次快照,就形成了一个快照链,虚拟机的c盘卷仍然挂载在快照链的最末端,即虚拟机的写操作全就会落盘到最末端的快照卷中。该特点造成了一个问题,就是假如一共做了10次快照,这么在恢复到最新的快照点时,则须要通过合并10个快照卷来得到一个完整的最新快照点数据;若果是恢复到第8次快照时间点,这么就须要将前8次的快照卷合并成为一个完整的快照点数据。从这儿可以看出ROW的主要缺点是没有一个完整的快照卷,其快照之间的关系是链式的,假如快照层级越多,进行快照恢复时的系统开支会比较大。
读源卷
当读取数据时,假若即将读取的位置自先前快照后进行了写重定向,则须要对写重定向的位置进行读重定向;反之,就不须要。
图1-8读源卷
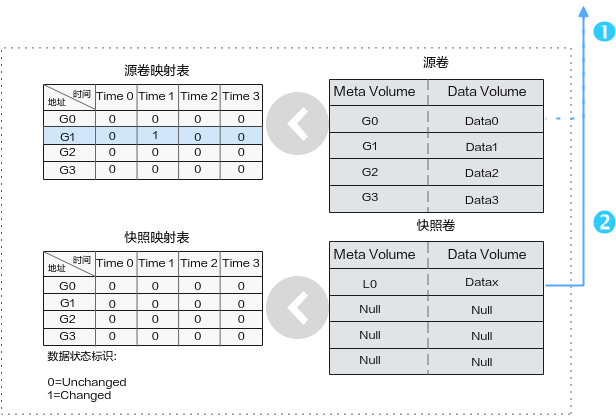

应用服务器在Time2下发读源卷的恳求:读取G1位置的源卷数据。G1位置在Time1时刻进行了重定向写,则读重定向到快照卷L0中读取数据。
刚创建的快照不包含任何实际数据,只包含了指向源文件系统数据的入口表针,当用户访问快照数据时,实际上访问的是源文件系统中的数据。只有当源文件系统的数据发生变化后,快照才能引入其独有的数据,这部份数据因为受快照保护,故而不能直接删掉,只有等快照被删掉后,这部分空间才才能被释放。
随着源文件系统不断被更新敖青云存储技术原理分析:基于linux 2.6内核源代码,原有的数据块会逐渐的弄成快照的占用空间,而且新写入的数据,不会计入快照占用空间中,由于快照所映像的只是生成快照时刻的源文件系统映像。当用户须要恢复出快照点时刻的数据时,可通过快照数据的回滚快速实现,通过回滚,文件系统可将数据恢复到快照点时刻,因而避开了快照点后由于人为的错误或则病毒的入侵等造成的源文件系统受损导致的数据遗失。
须要说明的是,快照的回滚是不可逆的,回滚只能将数据恢复到某一特定的时间点,但该时间点以后的数据包括快照将会遗失。假如仅仅是特定的几个文件被毁坏、误更改、误删掉,则无需进行整个文件系统的回滚,可以直接从特定时间的快照上将这种文件自动拷贝到源文件系统中即可。另外,因为快照回滚会造成文件系统数据或快照遗失,假如用户正在访问这部份遗失的数据,有业务中断的风险,用户须要慎重使用。
ROW异同点
优势:不会增加源数据卷的写性能。源数据卷创建快照后的写操作会被重定向,所有的写I/O都被重定向到新卷中,而所有快照卷数据(旧数据)均保留在只读的源数据卷中。因而更新源数据只须要一个写操作,解决了COW写两次的性能问题。对于分布式系统来说,正是因为数据的分散,因而提供了并发读的机会。所以在分布式储存上,ROW的连续读写性能比COW好。
劣势:
没有一个完整的快照卷。ROW的快照卷数据映射表保存的是源数据卷的原始副本敖青云存储技术原理分析:基于linux 2.6内核源代码,而源数据卷数据表针表保存的则是更新后的副本。因而,当创建了多个快照时,会形成一个快照链中国linux,使原始数据的访问快照卷和源数据卷数据的追踪以及快照的删掉将显得异常复杂。在恢复快照时会不断地合并快照文件,导致较大的系统开支。单机读性能增长。因为采用了重定向写,致使本来连续的数据分散到了c盘中,连续写弄成了随机写,导致读性能增长。
综上,COW的快照方法更适宜于读密集型应用,或则对储存设备容易出现写入热点(对于小范围内的数据频繁写入)的应用,由于数据的更改都局限在小范围内,对同一份数据进行多次写只会出现一次复制操作。ROW适宜写密集的应用,同时因为ROW重定向写的特点,在分布式储存中,读性能会更高。





