2019年7月17日,Cloudera官方博客发文开源了一个幕后工作许久的大数据储存和通用估算平台交叉的新项目——YuniKorn。据介绍,YuniKorn是一种轻量级的通用资源调度程序,适用于容器编排系统,负责为大数据工作负载分配/管理资源,包括批处理作业和常驻运行的服务。
以下为博客原文的译文
HelloWorld,早已有一段时间了!
明天我们十分激动地宣布开源我们在幕后工作了许久的大数据储存和通用估算平台交叉的一个令人激动的新项目-YuniKorn!-一个新的独立通用资源调度程序开源调度系统,负责为大数据工作负载分配/管理资源,包括批处理作业和常驻运行的服务。
让我们一上去深入了解一下!
介绍
YuniKorn是一种轻量级的通用资源调度程序,适用于容器编排系统。它的创建是为了一方面在大规模,多住户环境中有效地实现各类工作负载的细细度资源共享,另一方面可以动态地创建云原生环境。YuniKorn为混和工作负载提供统一的跨平台调度体验linux系统,包括无状态批处理工作负载和状态服务,支持但不限于YARN和Kubernetes。YuniKorn[‘ju:nikɔ:n]是一个虚构的词,“Y”代表YARN,“K”代表K8s,“Uni”代表统一,其发音与“Unicorn”相同。创建它是为了最初支持这两个系统,但最终目的是创建一个可以支持任何容器协调器系统的统一调度程序。
YuniKorn目前有4个组件
我们将在下边稍后深入讨论那些问题。
背景
企业用户在不同的平台上运行工作负载,比如YARN和Kubernetes。她们须要使用不同的资源调度程序,便于规划其工作负载有效地在这种平台上运行。目前,调度程序生态系统是分散的,但是在平衡现有用例(如批处理工作负载)以及云本机体系结构,手动扩充等新需求方面的实现不是最理想的。诸如:
YARN具有批量工作负载的CapacityScheduler和FairScheduler。
K8s具有服务的默认调度程序。对于批处理工作负载,社区有Kube-batch,Poseidon,Rubix(Spark的Scheduler扩充)。
我们调查了这种项目,并意识到到目前为止还没有一个完美的方案来支持无状态批处理作业(须要公正性,高调度吞吐量等)和常年运行服务(须要持久化储存,复杂的编排约束,等等。)。这使得我们必须创建一个统一的调度框架来满足所有那些重要需求,并使大数据和云原生社区受惠。
构架
YuniKorn的其中一个设计目标是将调度程序与下边的资源管理系统分离,因此,我们创建了一个定义通讯合同的通用调度程序插口。通过借助它,scheduler-core和shim一起工作来处理调度恳求。关于YuniKorn组件的解释如下。
图:YuniKorn构架
YuniKorn的主要模块
YuniKorn-scheduler-interface:调度程序插口是资源管理平台(如YARN/K8s)将通过例如GRPC/编程语言绑定之类的API与之攀谈的具象层。

YuniKornCore:YuniKornCore封装了所有调度算法开源调度系统,它从资源管理平台(如YARN/K8s)下边搜集资源,并负责资源分配恳求。它决定每位恳求的最佳布署位置linux系统教程,之后将响应分配发送到资源管理平台。调度程序核心与上层平台无关,所有通讯都通过调度程序插口。
SchedulerShimLayers:调度程序Shim在主机系统内运行(如YARN/K8s),它负责通过调度程序插口转换主机系统资源和资源恳求,并将它们发送到调度程序核心。在作出调度程序决策时,它负责实际的pod/容器绑定。
SchedulerUI:调度程序UI为已托管的节点,估算资源,应用程序和队列提供简单视图。
YuniKorn的一些特点
以下是YuniKorn目前支持的调度功能列表:
同时,YuniKorn作为调度程序对K8S的一些支持如下:

用于监控YuniKorn队列资源使用情况的WebUI
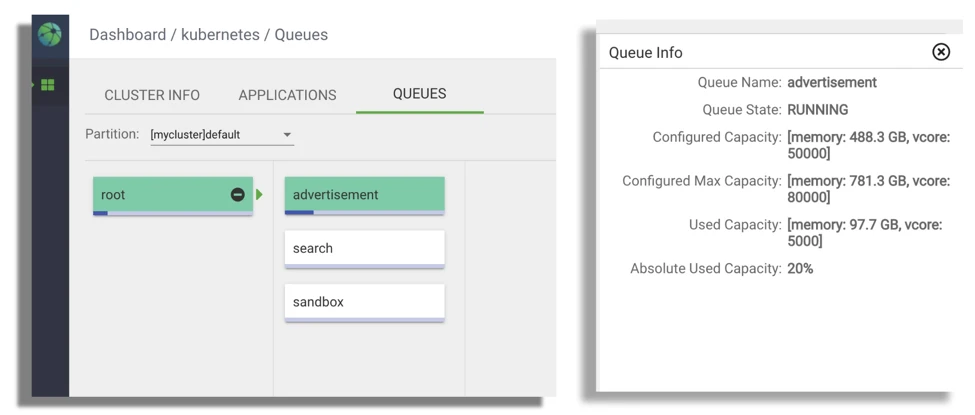
YuniKornWebUI
用于监控YuniKorn应用程序管理和资源使用情况的WebUI
YuniKorn用于监控的WebUI

下一步工作?
在单一系统上运行混和负载存在许多的挑战,YuniKorn是我们准备让这条路径更容易的选择。我们的目标是开始支持各类大数据工作负载运行在K8S集群之上。同时,我们正在努力更好地支持K8S上的Spark,Flink和Tensorflow等工作负载。我们的最终目标是为大数据和云原生世界带来最佳的调度体验。
作者介绍:
WeiweiYang,Cloudera的软件工程师,ApacheHadoop递交者和PMC成员,专注于分布式系统上的资源调度。
WangdaTan,Cloudera的K8S/Yarn团队资深软件工程师总监,ApacheHadoopPMC成员和递交者。自2011年以来的ApacheHadoop。资源管理,调度系统,估算平台的深度学习。
SunilGovindan,Cloudera软件工程总监。自2013年以来的ApacheHadoop项目,贡献者,递交者和PMC成员。HadoopYARN调度。
WilfredSpiegelenburg,Cloudera软件工程师。6年的ApacheHadoop开发经验,主要在YARN,MapReduce和Spark。
VinodKumarVavilapalli,Hortonworks/Cloudera的工程经理。ApacheHadoopPMC主席。ASF会员。ApacheHadoop创始团队成员之一。主要精力在大数据,大规模调度,容器化支持,扩充性及开源社区。
原文链接:





